
I am a researcher/engineer with a strong background in computer vision and machine learning. I am interested in developing algorithms for real-world applications. Currently, I am working on object detection and tracking at Xovis AG, Switzerland since October 2023.
I was a postdoctoral researcher with Prof. Luc Van Gool in the Computer Vision Lab at ETH Zurich for 2020 to 2023. I received a Doctor of Philosophy (PhD) in the Artificial Intelligence and Vision Group at Oxford Brookes University in 2019. I was advised by Dr. Fabio Cuzzolin. My PhD research was focused on spatio-temporal action detection and prediction in realistic videos.
Earlier, I was research engineer for two years in imaging and computer vision group at Siemens research India, directed by Amit Kale. In 2013, I graduated from masters in informatics (MOSIG) program at Institut National Polytechnique de Grenoble-INPG (School ENSIMAG) with specialization in Graphics Vision and Robotics (GVR). I completed my master's thesis under the supervision of Dr. Georgios Evangelidis and Dr. Radu HORAUD at INRIA, Grenoble. I received Bachelor of Technology degree in Electronics and Instrumentation Engineering from VIT University, Vellore, during which I had chance do an internship at university of Edinburgh under the supervision of Dr. Bob Fisher.
I love to participate in challenges and contests. Here are some of my recent participations.
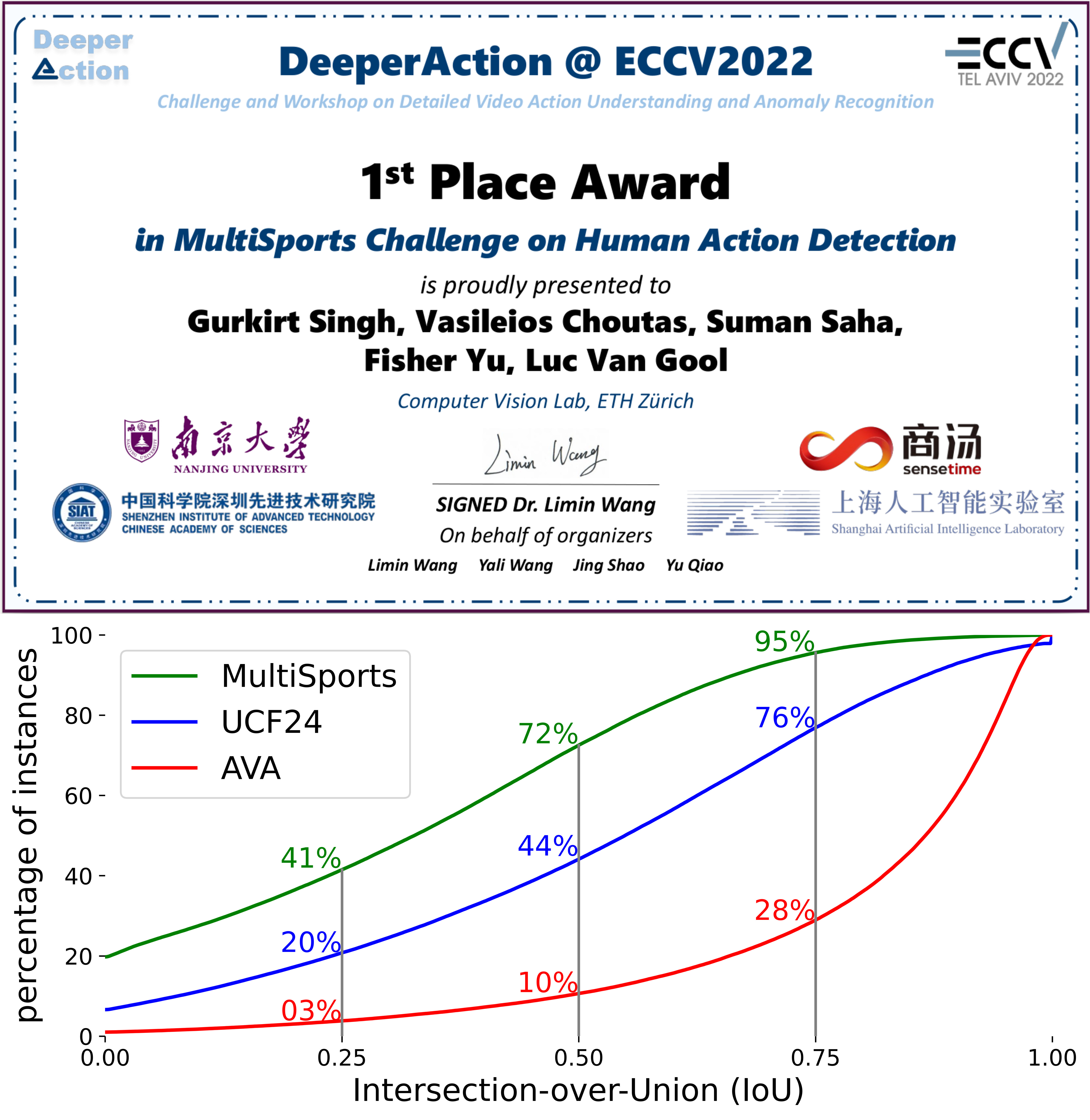
MultiSports Challenge, 2022: Spatio-temporal action detection, Rank: 1/15.
Charades Challenge, 2017: Acton Recognition, Rank: 2/10, Temporal Action Segmentation, Rank: 3/6.
ActivityNet Challenge, 2017: Untrimmed Video Classification, Rank: 3/29.
ActivityNet Challenge, 2016: Untrimmed Video Classification, Rank: 10/24, Actvity detection, Rank: 2/6.
ChaLearn Looking at People Challenge, 2014 , Gesture detection, Rank: 7/17.
ChaLearn Looking at People Challenge, 2013 , Gesture detection, Rank: 17/54.


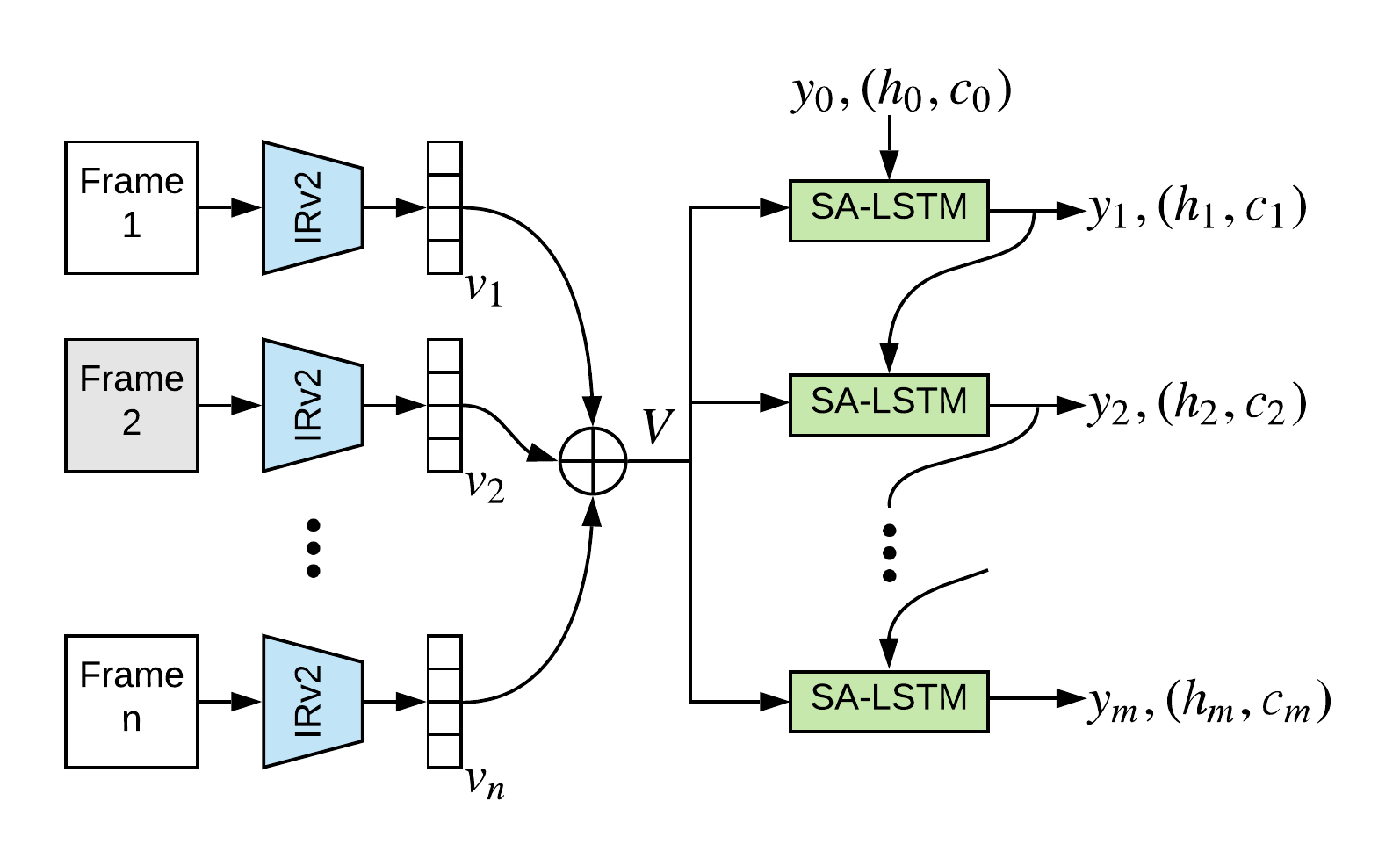
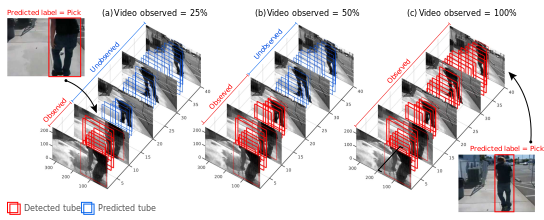
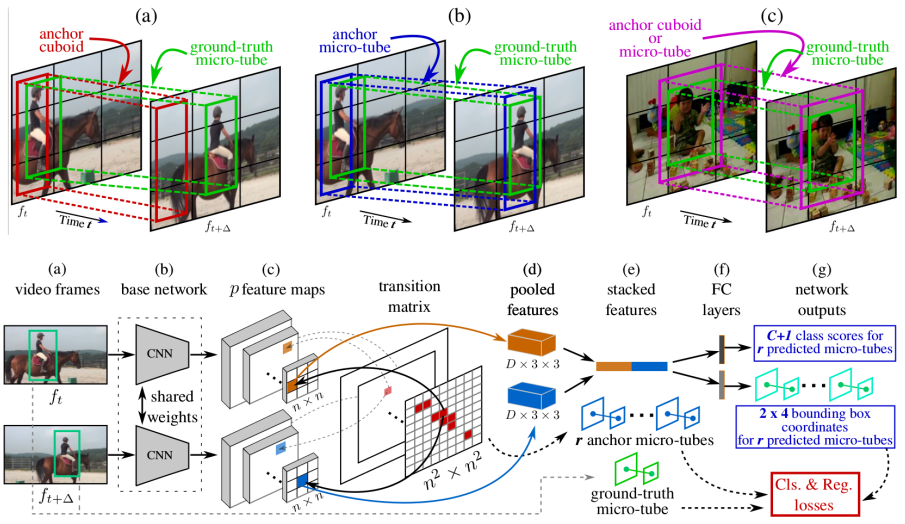
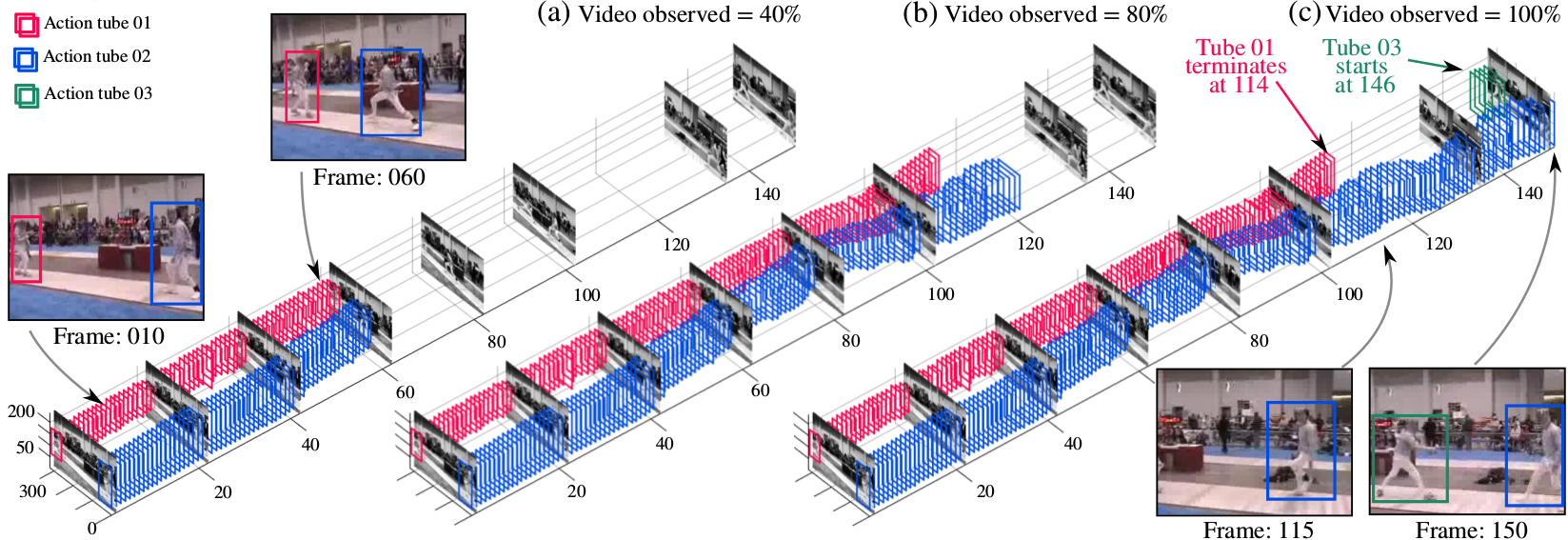
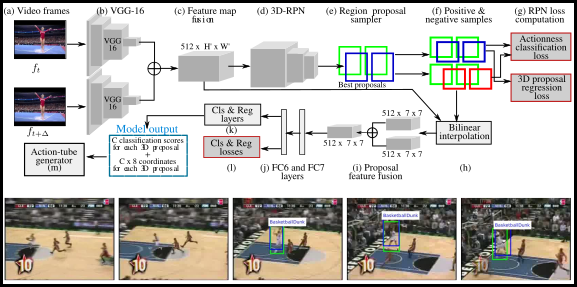
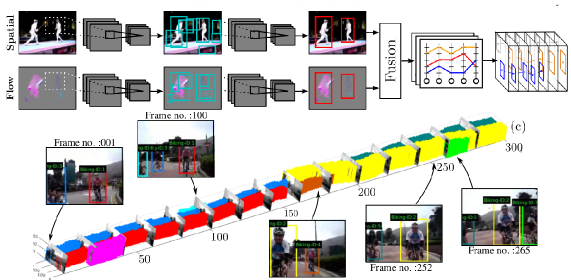
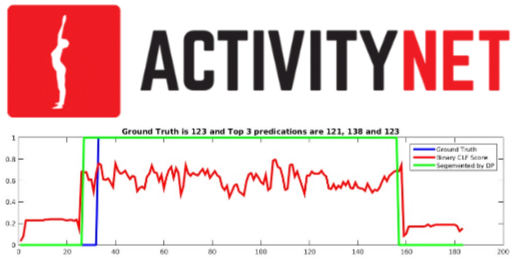
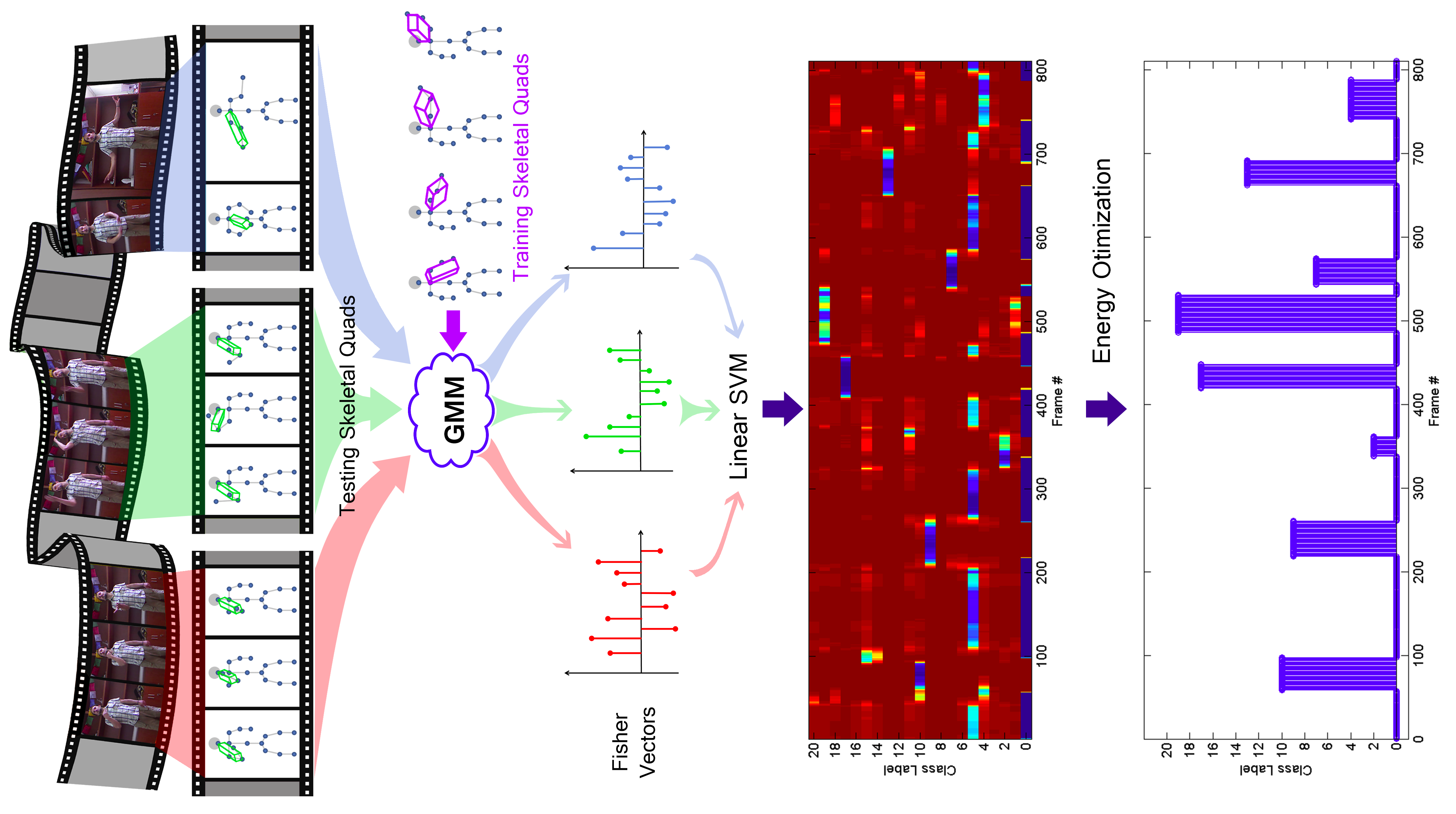
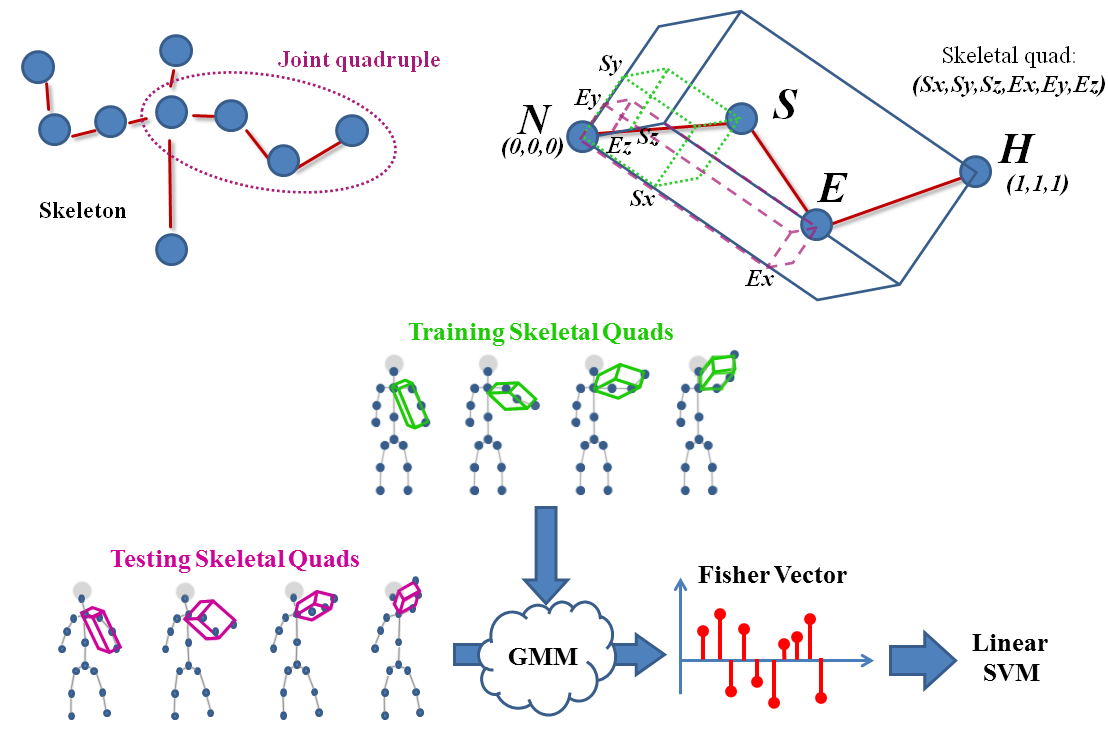
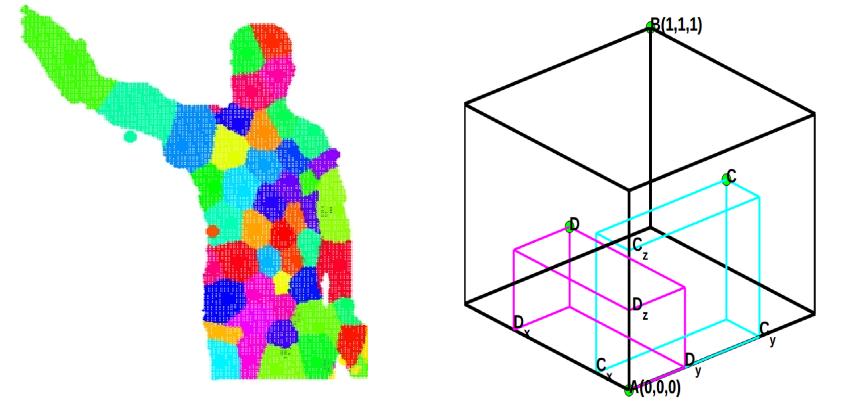

I made an attempt to compile recent works on action recognition in more searchable format. Check it out on my older page
My old research page, it has an intresting review of action recognition and prediction works.
Citation Graph: part of submission from reading Group-1 at ICVSS 2016 (only works in firefox)